
Biostatistics & Bioinformatics
- Research assistants:
- Technician:
Building on this role, the Unit operates across the full data lifecycle, from experimental planning through data acquisition and quality control to statistical evaluation and integrative interpretation. Particular emphasis is placed on longitudinal and high-dimensional datasets, where appropriate modelling strategies are essential for correct biological interpretation. In practice, the Unit works closely with all CCP platforms, linking molecular, imaging, physiological, and behavioral readouts into coherent analytical frameworks rather than isolated outputs.
A key function of the Unit is to ensure that data generated across CCP are comparable, interpretable, and reusable through standardization of data structures, implementation of robust statistical workflows, and integration of datasets across studies and modalities. This enables evaluation of experimental findings in a broader biological context and supports downstream decision-making in disease modelling and preclinical research.
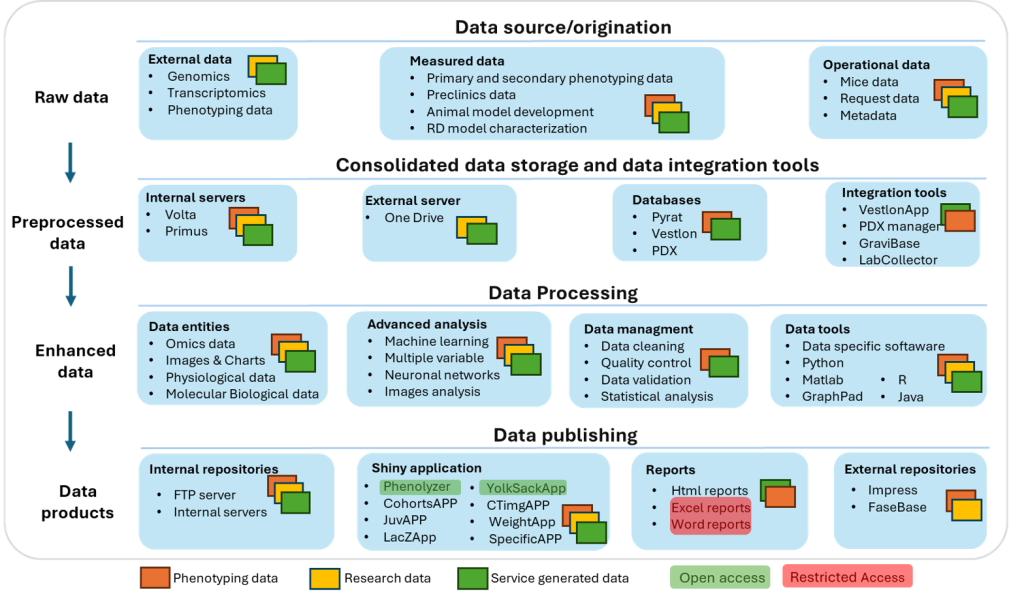
The Unit also develops tailored analytical solutions where standard approaches are insufficient, including advanced statistical models, automated pipelines, and machine learning-based tools for complex data types such as imaging or physiological signals. In parallel, it ensures data governance across CCP, including curation, metadata standardization, and preparation of datasets for dissemination in accordance with FAIR principles, supporting long-term usability and reproducibility.
Services Data Management and Governance
The Unit ensures that all data generated within CCP is handled in a consistent, traceable, and reusable manner. This includes implementation of standardized data structures, quality control procedures, and metadata annotation using controlled vocabularies and ontologies. Data are prepared for internal use as well as for dissemination through public repositories in accordance with FAIR principles. The underlying infrastructure combines automated pipelines with curated data handling, ensuring both efficiency and long-term usability of datasets across projects and collaborations.
The underlying infrastructure combines automated pipelines with curated data handling, ensuring both efficiency and long-term usability of datasets across projects and collaborations.
Data Management and Workflow at CCP:
Services Experimental Design and Statistical Planning
The Unit supports experimental planning at the earliest stages of a project, where correct design is critical for obtaining interpretable and translatable results. This includes definition of study structure, selection of appropriate statistical frameworks, power analysis, and implementation of randomization strategies tailored to animal studies. Particular attention is given to the definition of primary and secondary endpoints and to minimizing bias in complex experimental setups. These activities are performed in close interaction with experimental teams, ensuring that downstream analyses are statistically sound and aligned with biological objectives.
Services Data Analysis and Statistical Modelling
The Unit provides comprehensive statistical analysis of phenotyping data, ranging from standard comparisons to advanced modelling approaches required for structured and longitudinal experiments. Analyses are typically implemented in R- and Python-based environments using validated and reproducible workflows. Depending on the study design, this includes mixed-effects models, time-series analysis, and multivariate approaches suitable for high-dimensional datasets. Emphasis is placed not only on statistical significance, but on correct biological interpretation and robustness of conclusions across cohorts and experimental conditions.
Services Omics and High-Throughput Data Analysis
High-throughput datasets are processed and interpreted using established computational pipelines adapted to CCP workflows. The Unit supports analysis of next-generation sequencing data, including whole genome sequencing, RNA-seq, and ChIP-seq, as well as metabolomics, lipidomics, and MALDI-derived datasets. Data processing includes normalization, quality control, feature extraction, and downstream statistical interpretation. Whenever required, analyses are extended to pathway-level interpretation and integration with phenotypic outputs, enabling mechanistic insight rather than isolated data reporting.
Services Data Integration and Multimodal Analysis
A key capability of the Unit is the integration of heterogeneous datasets generated across CCP platforms. Molecular, imaging, physiological, and behavioral data are combined into unified analytical frameworks, allowing complex phenotypes to be interpreted across biological scales. This involves harmonization of data formats, alignment of experimental metadata, and application of multivariate and data-driven approaches to identify relationships between modalities. The goal is to move beyond single-readout analysis towards a systems-level understanding of phenotype and treatment response.
Do you have questions? Ask us
Advanced data science Advanced Computational Modelling and Data Science Approaches
The Unit applies advanced data science methodologies to extract predictive and mechanistic insight from complex biological datasets. This includes development of statistical and machine learning models for phenotype prediction, classification, and clustering of heterogeneous data. These approaches are continuously adapted and extended to reflect the structure and complexity of CCP-generated datasets, particularly in high-dimensional and non-linear biological systems.
Advanced data science Automated Phenotyping and Image Data Science
Data science approaches are used to enable automated and scalable phenotyping from imaging data. This includes development of pipelines for microCT-based morphometry, retinal analysis from OCT datasets, and segmentation-driven analysis of skeletal and organ-level structures. Emphasis is placed on reproducibility, quantitative robustness, and direct integration into experimental workflows.
Advanced data science Physiological Data Science and Signal Processing
The Unit develops and applies data science strategies for the analysis of physiological and behavioral data, where raw signals are often noisy and complex. This includes ECG, calorimetry, and behavioral tracking data, processed through advanced filtering, feature extraction, and modelling approaches. These methods enable reliable interpretation of dynamic biological processes and are refined in parallel with their application.
Advanced data science Custom Data Science Tools and Pipeline Development
To support complex and non-standard experimental designs, the Unit develops custom data science tools and analytical pipelines. These include automated workflows for high-throughput data processing and interactive platforms for data exploration and visualization. All developments are driven by real experimental needs, ensuring immediate applicability within CCP phenotyping and preclinical pipelines.
Do you have questions? Ask us
Technology platforms


Biostatistics / Bioinformatics unit was established with the support from OP RDE project CZ.02.1.01/0.0/0.0/16_013/0001789 – Upgrade of the Czech Centre for Phenogenomics: developing towards translation research. ITC infrastructure was expanded with the support from the project CZ.02.1.01/0.0/0.0/18_046/0015861 CCP Infrastructure Upgrade II.
